해당 Spark 관련 설정은 Cloudera Data Platform 기반의 환경에서 테스트 되었으며, 기본적으로 YARN을 통한 Spark Applcation의 리소스를 관리한다. 추가적으로, YARN / Mesos / Standalone Cluster Manager / Kubernetes 통한 리소스 관리가 가능하다.
장기간 프로세스가 실행되어 CDC 작업을 수행하기 위해서는, 캐싱되어 있는 Kerberos ticket에 대한 재발행 (delegate token의 갱신)이 필요하다.
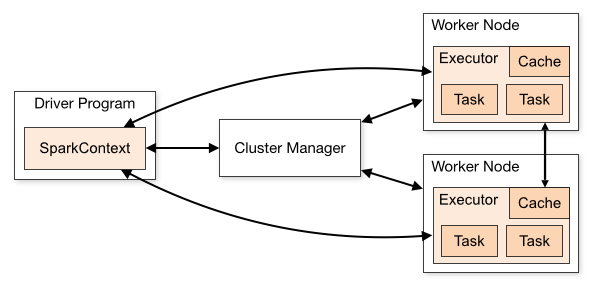
spark application을 배포하기 위해 필요한 Kerberos 관련 설정 정보를 정리해본다. 관련 설정 정보를 정리하기 전, 구분이 필요한 Client, Cluster mode에 대해서 짧게 정리해본다.
Client Mode
Spark Driver는 Cluster 외부의 Machine에서 실행되며, 나머지 Worker는 Cluster에 위치해 있다.
Cluster Mode와 비슷하지만 다른 점은 Application을 제출한 Client Machine에 Spark Driver가 위치한다.
주로, 개발단계에서 테스트, 디버깅을 위해 사용한다.
Cluster Mode
하나의 Worker Node에 Spark Driver를 할당하고, 다른 Worker Node에 Executor를 할당한다.
YARN을 사용하는 경우, Driver Node가 죽더라도 Failover가 자동적으로 수행되므로 Production에서 사용한다.
spark-submit 명령에서 YARN Cluster 모드에서만 이를 위한 --principal --keytab 옵션이 사용 가능하다.
Spark on YARN and Kubernetes only:
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--principal PRINCIPAL Principal to be used to login to KDC.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above.
#The keytab is copied to the host running the ApplicationMaster, and the Kerberos login is renewed periodically by using the principal and keytab to generate the required delegation tokens needed for HDFS.
https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
옵션정보
: 애플리케이션의 주 진입점인 메인 클래스입니다.
: Kerberos 주체(사용자)의 원하는 principal입니다.
: Kerberos 주체의 keytab 파일 경로입니다.
: 로그인 설정 파일인 login.conf의 경로입니다. 이 파일은 Kerberos 보안 설정을 정의하는 데 사용됩니다.
위 명령어에서 중요한 설정은 다음과 같습니다:
--master yarn: YARN 클러스터를 사용한다는 것을 나타냅니다.
--deploy-mode cluster: 애플리케이션을 클러스터 모드로 배포한다는 것을 나타냅니다.
--principal과 --keytab: Kerberos 주체와 해당 주체의 keytab 파일을 지정합니다.
--conf "spark.yarn.keytab="과 --conf "spark.yarn.principal=": Spark가 YARN과 상호작용할 때 사용할 Kerberos 주체와 keytab 파일을 지정합니다.
--conf "spark.yarn.security.tokens.hive.enabled=false"과 --conf "spark.yarn.security.tokens.hbase.enabled=false": Hive 및 HBase와 같은 다른 보안 토큰을 사용하지 않도록 설정합니다.
--conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=": Executor에 대한 추가 Java 옵션을 설정하여 로그인 설정 파일을 지정합니다.
위와 같이 설정하면 spark-submit을 사용하여 Spark 애플리케이션을 클러스터 모드로 배포할 수 있습니다.
#### spark3-submit
spark3-submit --master yarn \
--keytab /etc/security/keytabs/tester1.keytab \
--principal tester1@GOODMIT.COM \
--jars /opt/cloudera/parcels/CDH/lib/kudu/kudu-spark3_2.12.jar \
--driver-java-options "-Djava.security.auth.login.config=/etc/security/keytabs/jaas.conf" \
--conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=/etc/security/keytabs/jaas.conf" \
--conf "spark.driver.extraJavaOptions=-Djava.security.auth.login.config=/etc/security/keytabs/jaas.conf" \
/root/spark/kudu_test.py
writeStream에서 Kudu에 쓰기 작업을 수행할 때 사용할 수 있는 옵션은 다음과 같습니다. 이러한 옵션들은 writeStream.format("org.apache.kudu.spark.kudu") 구문 다음에 option() 함수를 사용하여 설정합니다:
kudu.master: Kudu 클러스터의 마스터 주소를 지정합니다. 예를 들어, kudu.master 옵션을 kudu_master_address로 설정합니다.
kudu.table: 쓰기 작업을 수행할 Kudu 테이블의 이름을 지정합니다. 예를 들어, kudu.table 옵션을 kudu_table_name으로 설정합니다.
kudu.operation: 쓰기 작업의 종류를 지정합니다. 가능한 값으로는 "insert", "upsert", "update", "delete", "truncate", "insert_ignore", "insert_ignore_batch", "update_ignore", "update_ignore_batch" 등이 있습니다.
kudu.rowkeycolumns: Kudu 테이블의 RowKey 열을 지정합니다. 여러 개의 RowKey 열이 있는 경우 쉼표로 구분하여 설정합니다.
kudu.master_addresses: 여러 개의 Kudu 마스터 주소를 지정할 수 있습니다. 쉼표로 구분하여 설정합니다.
kudu.num_partitions: Kudu 테이블의 파티션 수를 설정합니다.
kudu.replica_update_mode: 데이터의 복제를 어떻게 처리할지 지정합니다. "LEADER" 또는 "CLOSEST_REPLICA" 값을 가질 수 있습니다.
kudu.write_mode: 데이터를 쓰는 모드를 지정합니다. "append" 또는 "upsert" 값을 가질 수 있습니다.
kudu.ignore_duplicate_row_errors: 중복된 행을 무시할지 지정합니다.
kudu.log_performance_metrics: 성능 메트릭 로깅을 활성화할지 지정합니다.
kudu.external_consistency: 외부 일관성 모드를 설정합니다. "STRONG" 또는 "EVENTUAL" 값을 가질 수 있습니다.
kudu.range_partition_columns: 범위 파티션의 기준 열을 지정합니다.
kudu.hash_partition_columns: 해시 파티션의 기준 열을 지정합니다.
kudu.hash_partitions: 해시 파티션 수를 지정합니다.
kudu.extra_configs: 추가적인 Kudu 설정을 지정합니다. 딕셔너리 형태로 옵션과 값을 설정합니다.
option("checkpointLocation", ...) or SparkSession.conf.set("spark.sql.streaming.checkpointLocation", ...)
위의 코드에서 groupBy와 agg 함수를 사용하여 primary_key 컬럼의 값이 같은 경우를 기준으로 데이터를 그룹화하고, collect_list 함수를 사용하여 같은 primary_key의 값을 리스트로 모아서 "values"라는 새로운 컬럼에 할당합니다. 이렇게 하면 primary_key 컬럼의 값이 같은 데이터는 그룹화되어 하나의 row로 표현되며, value 컬럼의 값들은 리스트로 모여있는 형태로 데이터를 추출할 수 있습니다. 결과에서 볼 수 있듯이, primary_key가 같은 경우에 해당하는 value들이 리스트로 모아져서 표현됩니다.