Parquet vs Apache ORC
Columnar, 컬럼형 저장 방식이란
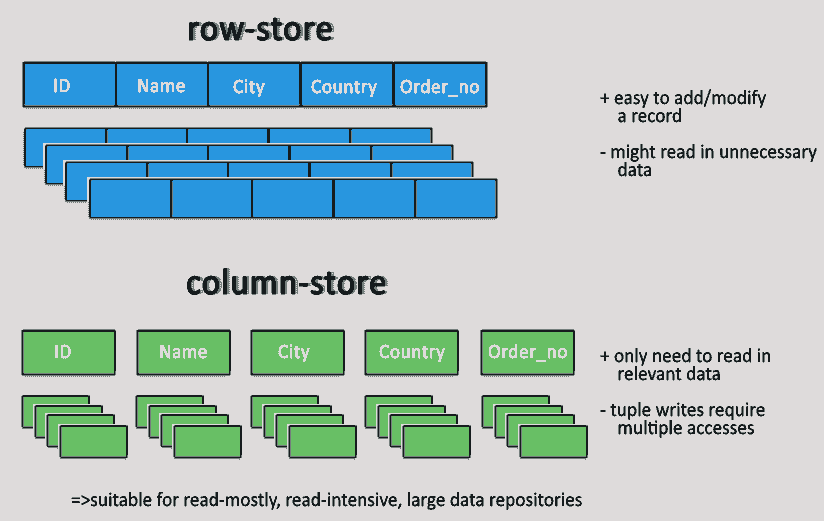
컬럼형 파일 형식은 행이 아닌 열 단위로 데이터를 저장하는 형식이다. 고성능 및 확장성이 필요한 데이터 웨어하우스 및 기타 스토리지 시스템에 적합하다.
특정 컬럼 조회시, 관련 컬럼에만 액세스하면 되므로 대규모 데이터 세트를 더 쉽게 쿼리하고 분석할 수 있다.
Apache ORC

Apache ORC는 Apache Hive의 처리 속도 향상과 Apache Hadoop 데이터 저장 효율 개선을 위해 개발되었다.
Apache ORC는 컬럼형 파일 포맷으로, 대용량 스트리밍 데이터 읽기에 최적화되어 있고, 필요한 행을 빠르게 찾는 데 필요한 통합 지원을 제공한다.
Apache ORC는 Hive에서 지원하는 모든 유형 세트를 지원하며, structs, lists, maps, and unions과 같은 복잡한 유형을 포함한다.
- Facebook은 데이터 웨어하우스에서 수십 페타바이트를 저장하기 위해 ORC를 사용하고, ORC가 RC 파일이나 Parquet보다 현저히 빠르다는 것을 입증했다.
https://engineering.fb.com/2014/04/10/core-infra/scaling-the-facebook-data-warehouse-to-300-pb/
- Yahoo는 제작 데이터를 저장하기 위해 ORC를 사용하며 일부 벤치마크 결과를 공개.
Apache Parquet
Apache Parquet는 Twitter와 Cloudera 간의 공동 개발, Hadoop의 창시자인 Doug Cutting이 만든 Trevni 컬럼형 저장 형식을 개선하기 위해 설계되었다.
Apache Parquet는 Apache Hadoop 생태계에서 사용되는 컬럼 지향 데이터 저장 형식이다. 이는 Hadoop의 다른 컬럼형 저장 파일 형식인 RCFile과 ORC와 유사하며, Hadoop 주변의 대부분의 데이터 처리 프레임워크와 호환된다.
Apache Parquet는 Apache Thrift 프레임워크를 사용하여 구현되어, C++, Java, Python, PHP 등과 같은 다양한 프로그래밍 언어로 작업할 수 있다.
2015년 8월 기준으로, Parquet는 Apache Hive, Apache Drill, Apache Impala, Apache Crunch, Apache Pig, Cascading, Presto 및 Apache Spark를 포함한 대규모 데이터 처리 프레임워크를 지원. 이는 pandas Python 데이터 조작 및 분석 라이브러리가 사용하는 외부 데이터 형식 중 하나.
Parquet VS ORC
Parquet의 장점
- 열 기반 저장: Parquet은 컬럼 중심으로 데이터를 저장, 디스크 I/O와 압축 효율을 높여 디스크에서 메모리로 전송되는 데이터 양을 줄이고 쿼리 성능을 빠르게 함.
- 스키마 진화: Parquet은 복잡한 중첩 데이터 구조를 지원, 스키마 진화(변화)를 허용. 즉, 데이터의 스키마가 진화함에 따라 Parquet은 이러한 변화에 적응할 수 있다.
- 압축: Parquet은 우수한 압축 및 인코딩 스키마 지원. 디스크 저장 공간을 줄이고, 특히 데이터 분석에서 흔한 열 기반 데이터 검색 성능을 향상.
Parquet의 단점
- 쓰기 중심 작업 부하: Parquet은 열 별로 압축 및 인코딩을 수행하기 때문에, 쓰기 중심 작업 부하에 대한 데이터 쓰기 비용이 높을 수 있다.
- 소규모 데이터 세트: 소규모 데이터 세트의 경우 Parquet의 열 저장 모델의 장점이 그리 두드러지지 않아 최선의 선택이 아닐 수 있다.
ORC의 장점
- 압축: ORC는 저장 공간을 최소화하는 압축률을 제공. 또한 파일 내에 저장된 가벼운 인덱스를 포함하여 읽기 성능을 향상.
- 복잡한 유형 지원: ORC는 구조체, 리스트, 맵, 유니언 타입을 포함한 복잡한 유형을 지원.
- ACID 트랜잭션: ORC 파일은 Hive에서 ACID 트랜잭션과 매우 잘 작동하며, 업데이트, 삭제 및 병합과 같은 기능을 제공.
ORC의 단점
- 커뮤니티 지원 부족: Parquet와 비교했을 때, ORC는 이 파일 포맷에 대한 커뮤니티 지원이 적어, 리소스, 라이브러리 및 도구가 더 적다.
- 쓰기 비용: Parquet와 마찬가지로, ORC는 열 기반의 특성으로 인해 높은 쓰기 비용을 가질 수 있다.
Parquet의 사용 사례
Parquet은 대규모, 복잡하고 중첩된 데이터 구조를 다룰 때, 특히 읽기 중심의 작업 부하나 Apache Spark 또는 Apache Arrow와 같은 도구를 사용하여 분석을 수행할 때 강점을 가짐. 열 저장 방식은 집계 쿼리가 일반적인 데이터 웨어하우징 솔루션에 매우 적합.
ORC의 사용 사례
ORC는 고속 쓰기가 필요한 경우에 자주 사용. 특히 Hive 기반 프레임워크와 함께 사용될 때 많이 사용되며, 데이터 수정(업데이트 및 삭제)이 필요한 경우에 잘 맞음(ACID 속성을 지원하기 때문).
ORC는 복잡하고 중첩된 데이터 유형을 사용할 때 좋음.
<parquet, orc table>
| Capability | Data Warehouse | ORC | Parquet | SQL Engine |
|---|---|---|---|---|
| Read non-transactional data | Apache Hive | ✓ | ✓ | Hive |
| Read non-transactional data | Apache Impala | ✓ | ✓ | Impala |
| Read/Write Full ACID tables | Apache Hive | ✓ | Hive | |
| Read Full ACID tables | Apache Impala | ✓ | Impala | |
| Read Insert-only managed tables | Apache Impala | ✓ | ✓ | Impala |
| Column index | Apache Hive | ✓ | ✓ | Hive |
| Column index | Apache Impala | ✓ | Impala | |
| CBO uses column metadata | Apache Hive | ✓ | Hive | |
| Recommended format | Apache Hive | ✓ | Hive | |
| Recommended format | Apache Impala | ✓ | Impala | |
| Vectorized reader | Apache Hive | ✓ | ✓ | Hive |
| Read complex types | Apache Impala | ✓ | ✓ | Impala |
| Read/write complex types | Apache Hive | ✓ | ✓ | Hive |